分布式系统监控中的数据聚合
《SRE》这本书有两章讲监控分布式系统,分别是第 6 章《Monitoring Distributed Systems》和第 10 章《Practical Alerting from Time-Series Data》。第 6 章讲的是原则,第 10 章讲了一些 Borgmon 的使用细节,题图来自这一章。本文想具体谈谈监控数据的聚合,这在书上一笔带过。 破题 假如一个银行有两个服务窗口,顾客在窗口一办理业务平均花 5 分钟,在窗口二花 10 分钟,一天下来,问所有顾客办理业务平均花多少时间?简单的算术平均数是 7.5 分钟,这是错的,正确的算法应该用调和平均数,2/(1/5 + 1/10) = 6.67 分钟。直观解释:在一个小时内,窗口一办理了 12 个业务,窗口二办理了 6 个业务,所以平均每个业务办理时间为 60*2 / (12+6) = 6.67 分钟。 分布式系统也是一样,从多台机器采集的数据很多时候不能简单地用算术平均来汇总。
系统规模 这里的系统不是指整个 google,而是其中某一个业务,例如(某一类)广告。 硬件方面,整个系统部署在全球十几二十个数据中心(书上叫 cluster),每个大洲(亚欧美)都有4个以上的数据中心,在每个数据中心占用几百上千台机器,系统的总“占地面积/footprint”有上万台机器。 软件方面,每个数据中心部署一套 serving stack。每个 serving stack 有多个 serving jobs,每个 serving job 有多个 serving tasks,也叫 replicas (题图中叫 application tasks,它没有区分 serving jobs),每个 task 就是一个进程。同一个 serving job 运行的是同一个可执行文件(binary)。serving stack 有 10 来个关键的 serving jobs,每个关键 serving job 有几百上千个 tasks。一个 serving stack 总共有几千上万个 tasks(进程),运行在数据中心那几百上千台机器上,每台机器运行若干个 tasks。task 运行在哪台机器是由 Borg 自动调度的。 不同数据中心的 serving stack 结构大体相同,区别在于容量不同,换句话说, serving jobs 相同,但 task replicas 不同。任何单个 task 或机器坏掉,不应该影响服务,也不需要人工介入。
这么大规模的系统,单独看任何一个serving task 都无法了解系统的当前状况,因此我们需要把监控数据聚合起来,这篇文章主要谈的就是如何聚合。 四个最主要的指标 第 6 章《监控分布式系统》提出了四个最基本的监控指标: - 流量(traffic),对于 Web 服务,通常是每秒 HTTP 请求数;对于 RPC 服务,通常是每秒调用数。
- 延迟(latency),完成一次请求所花的时间(毫秒)。
- 错误率(errors),例如每秒失败的请求数,或者错误率(error ratio),失败的请求占总请求数的比例。
- 饱和度(saturation),或者叫使用率(utilization),指的是系统的“热度”,数字越高,系统越热,通常延迟也会随之加大。通常是个百分比(0~100 算正常,高于 100 算过载),等于当前资源使用量除以资源配额。对于请求响应式的服务,utilization 大体正比于流量,当 utilization 达到 100 时的流量即是系统的容量(capacity)。
这些监控指标适用不同的聚合算法,用错了聚合算法会得到错误的汇总数据,简单的说是平均和加权平均的区别。
采集数据服务进程通过某种方式暴露一些内部指标(metrics),然后监控程序会定期(比如 1 分钟)采集所有服务进程的 metrics,采集得到的数据都有时间戳。所谓“聚合”,就是根据 serving tasks 的原始数据算出那个 serving job 的数据,最简单的例子:知道每个 task 的流量,那么 job 的流量是 tasks 流量之和。 这里有两点值得注意: - 服务器应该暴露原始计数值,而不是其导数。比如服务进程有一个 int64_t requests,记录从启动到现在一共响应了多少个请求,服务进程每收到一个请求就把 requests 递增1。这个 requests 要暴露给监控系统,监控系统会定期采集这个数值,存到时间序列 task:requests 中。当然,服务进程重启的话,requests 会归零,监控系统应该对此有准备。服务器不需要对监控系统暴露“过去一秒钟内服务了多少个请求”。
- 采样率。采样率太低的话,一些尖峰就被平滑掉了。举个例子,假如负载均衡的反馈控制回路(feedback loop)陷入了振荡(oscillation),系统的流量以较短的周期剧烈波动,而振荡周期小于监控系统的采样周期,那么从监控的流量图上是看不出振荡的,还以为系统运行平稳,而实际上系统在每个振荡周期的流量波峰都处于超载状态,使得错误率攀升。根据 Nyquist 采样定理,监控系统的采样率至少要大于振荡周期的 2 倍,才能从监控的时间序列图上看出振荡来。
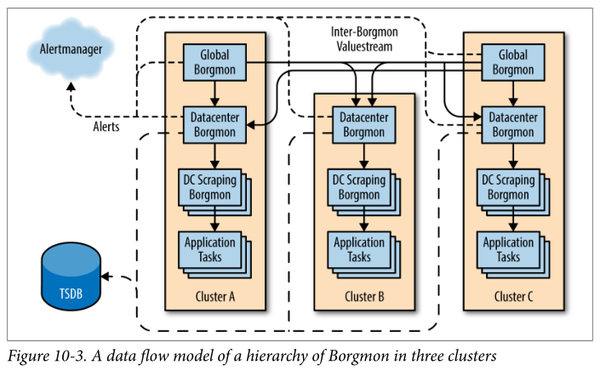
定期采集几千上万个服务进程的指标不是一件轻松的活,监控系统本身的伸缩性也要够好,才能监控上千台机器上万个进程的 serving stack。第 10 章提到了 sharding 的办法,题图正是这一做法的示意。 三种数据类型在讲数据聚合之前,先了解三种基本的数据类型,它们适用不同的聚合算法。这里我推荐先阅读 RRDtool - tutorial,这算得上是监控的始祖。这篇 tutorial 介绍了 Counter 和 Gauge 这两种类型,其中 Counter 就是我们下文提到的 Rate,但漏掉了另一个重要的 Ratio 类型。
- Rate,速率。例如流量(请求/秒),一般采集的是计数值(counter),对时间求导得 rate。用中学物理来类比,服务进程好比提供的是里程(distance),监控系统根据采样的数值和采样时间算出速度(speed)。对从多个 tasks 采集的 rate,通常 mean/max/min/sum 都是有意义的。
- Ratio,比率。比如 latency 和 error ratio,这是值得特别注意的一个类型,在聚合的时候要分子分母分别聚合,再相除。对多个 task 的 ratio, 通常 max/min 是有意义的,但是 mean/sum 无意义。拿服务进程的延迟来说,假如一个 serving job 有两个 tasks,task 1 的流量是 10 请求/秒,延迟是 10ms,task 2 的流量是 100 请求/秒,延迟是 20ms。我们知道“请求/秒”是 rate,可以相加,那么该 serving job 的总流量是 110 请求/秒。但是,该 serving job 的评价延迟该怎么算呢?简单的算术平均 (10+20)/2 = 15ms 是错的,正确的算法是 (20*100 + 10*10) / 110 = 19.1 ms。对于 error ratio 也是如此,两个 task 的 error ratio 分别是 0.0001 和 0.0002,那么 serving job 的 error ratio 很可能不是简单的平均数 0.00015,而是跟这两个 task 的流量有关。
- Gauge,刻度。比方说进程的 heap size(MB),每个服务进程的 data freshness(秒),job utilization 等等。通常 mean/max/min 是有意义的,sum 不一定有意义(想想温度,10 台机器的温度的平均值、最大值、最小值是有意义的,但温度之和就没意义了)。
如果 serving job 有 500 个 tasks,把 500 条线画在 dashboard 上将会是很壮观的一个数据带,我们一般想要一个汇总的数据,这就涉及数据聚合。 数据聚合(aggregate)
有了从某个 serving job 的每个 task 采集的数据,如何算出 job 级别的数据呢?下面对各种类型分别讨论。 Rate 的聚合是很容易,在第 10 章举了例子,书上用 dc 前缀是因为 serving job 在每个 serving DC 有一份部署。  注意 task:request:rate 是一个完整的变量名,其中前后的 task 和 rate 是纯粹是命名习惯,没有强制性。以下伪代码示例假定读者已经读过第 10 章,了解 Borgmon rules 的初步写法,并且省略了 variable 的 labels。
假如从 task 采集的原始数据是 task:requests,那么我们定义 task 流量为其导数:task:requests:rate = rate(task:requests)相应的 job 级别的聚合数据是简单对同一 job 的所有 tasks 求和:dc:requests:rate = sum(task:requests:rate)书上用 dc 前缀是因为 serving job 在每个 serving DC 有一份部署。平均每个 task 的流量:dc:requests:mean_rate = mean(task:requests:rate)
注意,dc:requests:rate 是先 rate 后 sum,不能是先 sum 后 rate,也就是说以下写法是错误的: // WRONGdc:requests:rate = rate(sum(requests))
原因是如果有 task 运行几天之后重启,其 requests 会归零,这就造成 sum(requests) 有较大负向波动,相应的 dc:requests:rate = rate(sum(requests)) 也就不准确了。如果用正确的算法,rate(requests) 会正确应对归零,那么 rate(requests) 会是 0,dc:requests:rate = sum(rate(requests)) 不会有波动。 Gauge 的聚合更容易,比如说对于服务进程的内存使用量: task 暴露 task:memory 这个指标,单位可以是 MB。job 总内存使用量:dc:memory:sum = sum(task:memory)平均每个 task 的内容使用量:dc:memory:mean = mean(task:memory)内存使用最多的 task:dc:memory:max = max(task:memory)
最难的是 Ratio 的聚合。以 latency 为例,首先,我们要求服务进程不只暴露一个数值,而应该暴露两个数:latency_numerator,latency_denominator 分别是分子和分母。每当完成一个请求,求出所花时间为 latency 毫秒,那么 latency_numerator += latency; // 分子加 latencylatency_denominator += 1; // 分母加 1
监控系统采集每个 task 的 latency_numerator 和 latency_denominator,保存在 task:latency_numerator 和 task:latency_denominator 在两个时间序列中。
// 先分别算出分子和分母的 rate:task:latency_numerator:rate = rate(task:latency_numerator)task:latency_denominator:rate = rate(task:latency_denominator)// task 的 latency 可以定义为两个 rate 之比:task:latency:ratio = task:latency_numerator:rate / task:latency_denominator:rate// 然后算出分子分母 rate 之和:dc:latency_numerator:rate = sum(task:latency_numerator:rate)dc:latency_denominator:rate = sum(task:latency_denominator:rate)// job 的 latency 可以定义为两个 sum 之比:dc:latency:ratio = dc:latency_numerator:rate / dc:latency_denominator:rate
为什么要这么复杂?因为只有这样才能正确聚合。读者可以找一些数据代入计算一下,应该就能明白。
全球聚合全球聚合由 global borgmon 完成,它会采集每个 DC 的 borgmon 的 dc:* 变量。 Rate,以全球流量为例: global:requests:rate = sum(dc:requets:rate))// 注意 mean(dc:requets:rate) 没有意义
Gauge,以全球内存使用量为例: global:memory:sum = sum(dc:memory:sum)global:memory:max = max(dc:memory:max)// 注意 mean(dc:memory:sum) 和 mean(dc:memory:mean) 没有意义
Ratio,以全球延迟为例:
// 先定义分子和分母global:latency_numerator:rate = sum(dc:latency_numerator:rate)global:latency_denominator:rate = sum(dc:latency_denominator:rate)// 最后算出 latencyglobal:latency:ratio = global:latency_numerator:rate / global:latency_denominator:rate
这里大家明白为什么前面要定义 dc:latency_numerator:rate 和 dc:latency_denominator:rate 了吧? 直方图的聚合对于数据的分布,一般采用直方图聚合,比如要想知道整个 serving job 的 95 percentile 延迟是多少毫秒,取每个 task 的 95 percentile 延迟的平均数是错的。正确的是把直方图的每个 bucket 分别加起来,再找出 95 percentile 在哪里。限于篇幅,这里就不举例了。 不要只看聚合后的数据有时候,从聚合之前的 task 级别数据能帮我们找出 outliers,能更快地定位问题。这要求可视化工具能支持同屏显示几百上千条数据曲线。虽然现在很多开源监控工具的界面很 fancy,能输出这么多数据点的曲线而不崩溃或失去响应恐怕不多见吧。
| 


 转播
转播 分享
分享 淘帖
淘帖 ()
()